1Learning Outcomes¶
Compare SIMD-extended matrix multiplication with sequential programs.
Compare performance using different
gccoptimization flags:-O0,-O2,-O3.
🎥 Lecture Video
Before continuing, we recommend reviewing the DGEMM benchmark and the performance optimizations we tried on a SISD architecture.
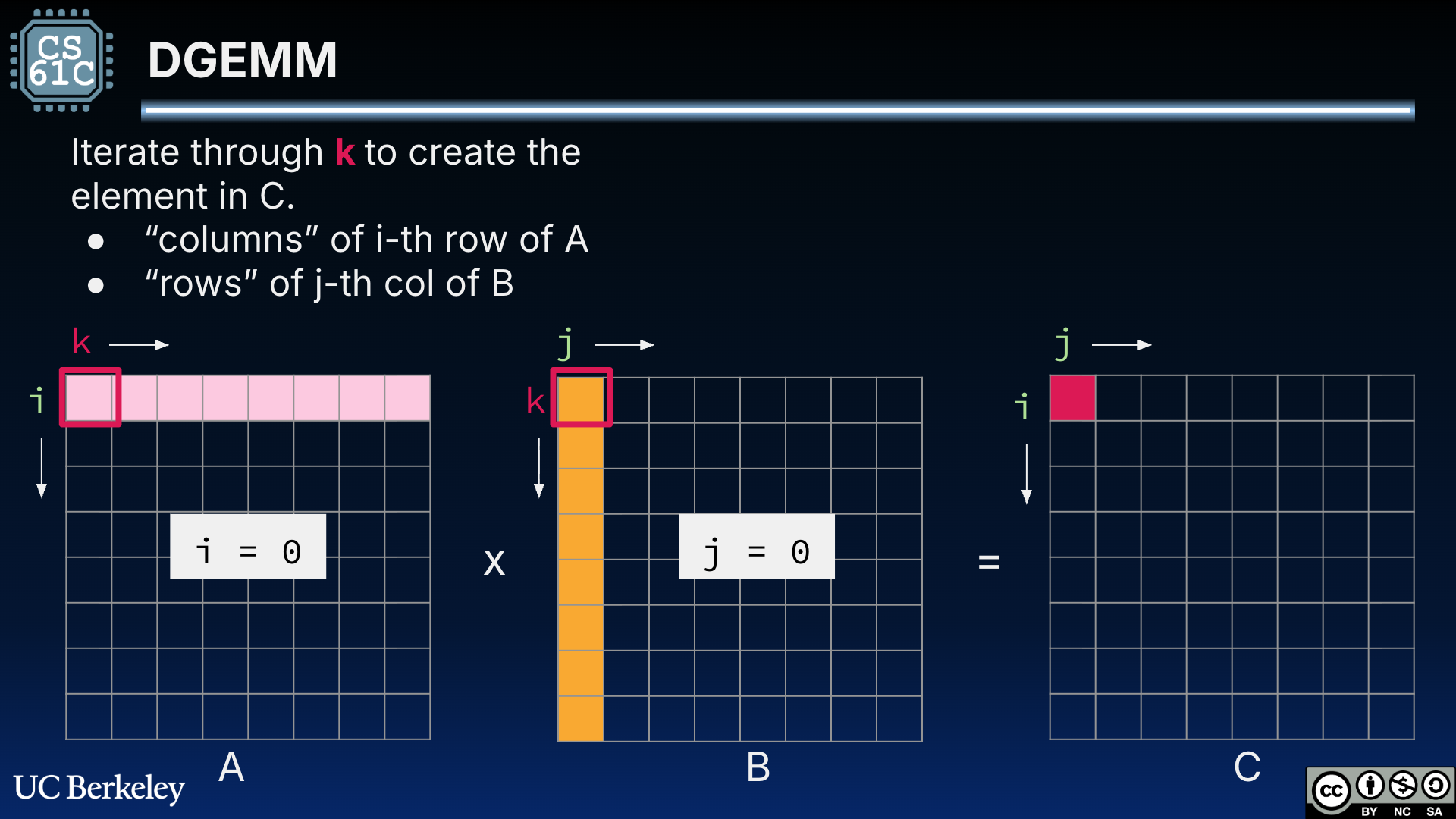
Figure 4:DGEMM for square matrices A and B. is computed as the dot product of row i = 0 of A and column j = 0 of B.
2DGEMM 7: Naive SIMD DGEMM¶
With the ability to perform SIMD multiplication, it is tempting to use our new 256-bit-wide registers to load in blocks of row A and blocks of column B for the element-wise multiplication necessary for dot products, as shown in Figure 1.
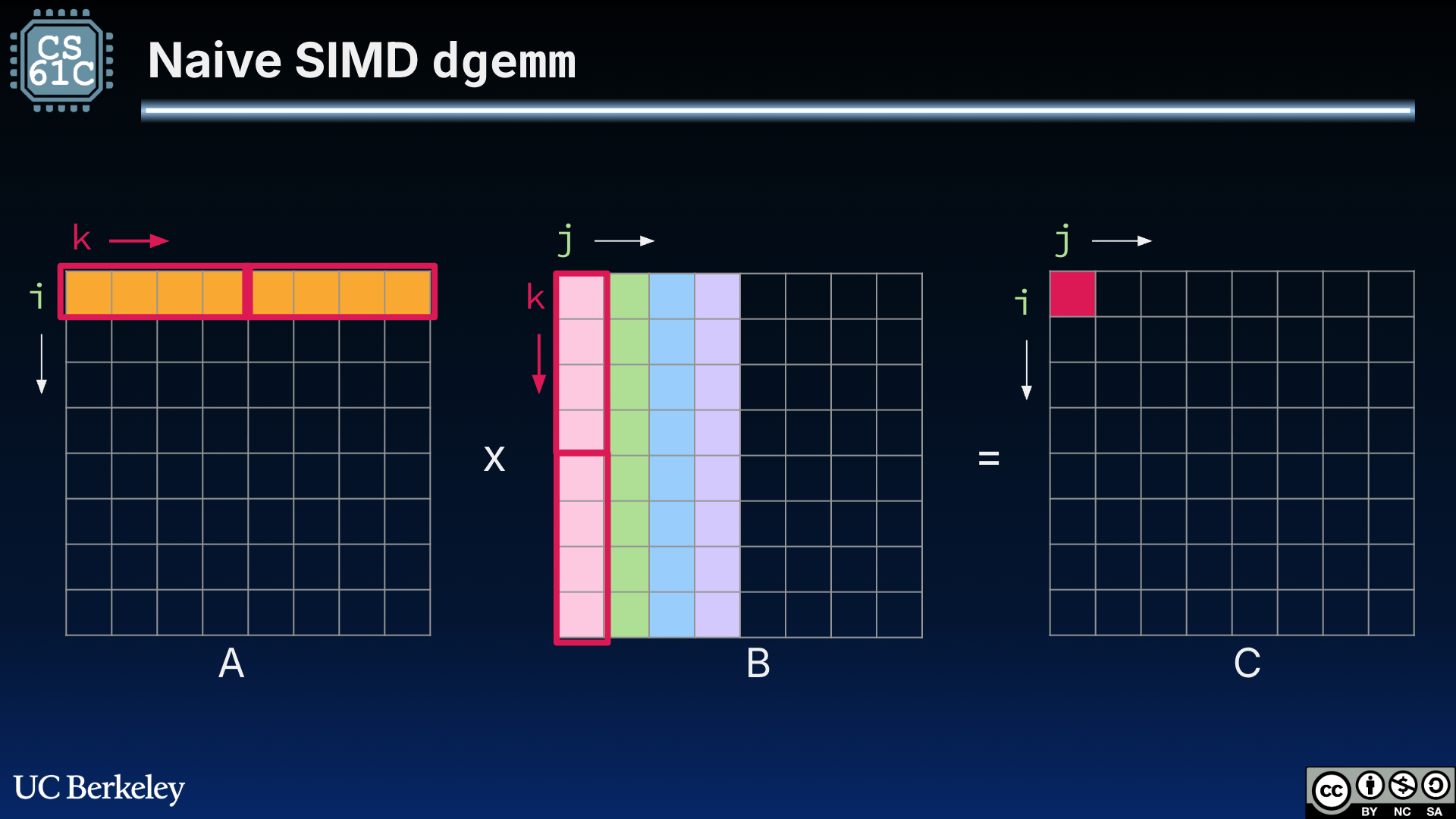
Figure 1:“Naive” SIMD DGEMM that leverages SIMD architecture registers to parallelize multiplications within a single dot product. The outlined boxes indicate which values are loaded into the 256-bit-wide registers.[1]
This naive SIMD implementation does better than our naive DGEMM but worse than specifying narrow registers with the register keyword in C:
C 0.768672 seconds
registers: 0.277462 seconds
simd,naive: 0.416584 secondsThe non-compulsory cache miss persists in our naive SIMD implementation—we are still loading in multiple rows of B instead of columns of B.
3DGEMM 8: Transpose SIMD DGEMM¶
We next apply cache blocking by first transposing B, then leveraging our 256-bit-wide (four-double) registers for element-wise multiplication:
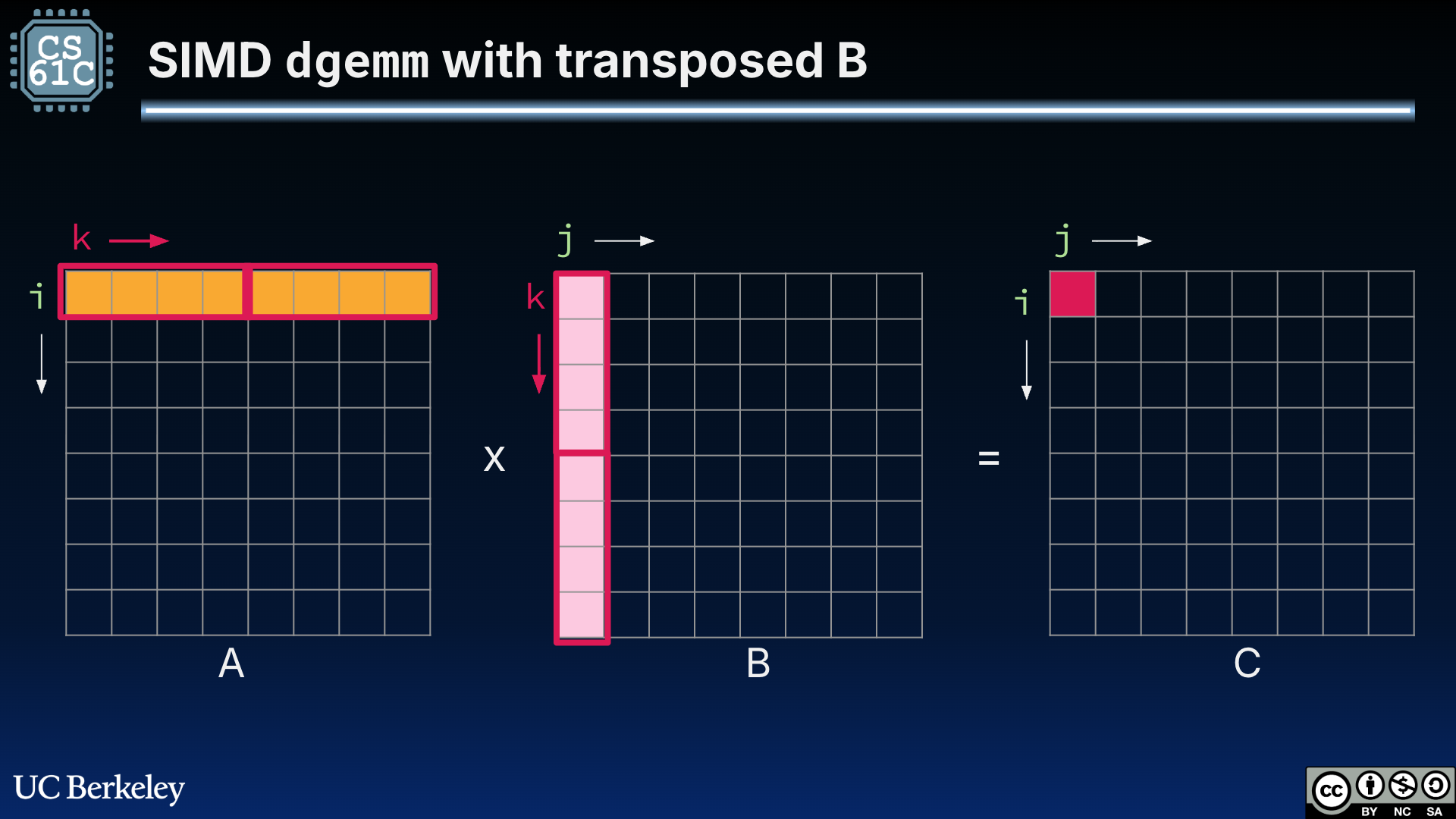
Figure 2:“Transposed” SIMD DGEMM that uses a transposed B to load in columns of B to streamline memory accesses. The outlined boxes indicate which values are loaded into the 256-bit-wide registers.
C 0.768672 seconds
registers: 0.277462 seconds
simd,naive: 0.416584 seconds
simd,transpose: 0.275622 secondsThis version is certainly speedier, but it does not prove huge benefits beyond our register keyword approach.
4DGEMM 9: Tiled SIMD DGEMM¶
Recall that cache blocking is any re-design of our algorithm to adjust memory accesses. Earlier, we discussed a submatrix tiling approach to matrix multiplication—where we compute multiple elements of C with the current set of rows of A and set of columns of B.
In Figure 3, we assume that the product of a scalar with a vector can be computed as a vector operation, provided that the scalar is copied to each element in a vector of the same length.
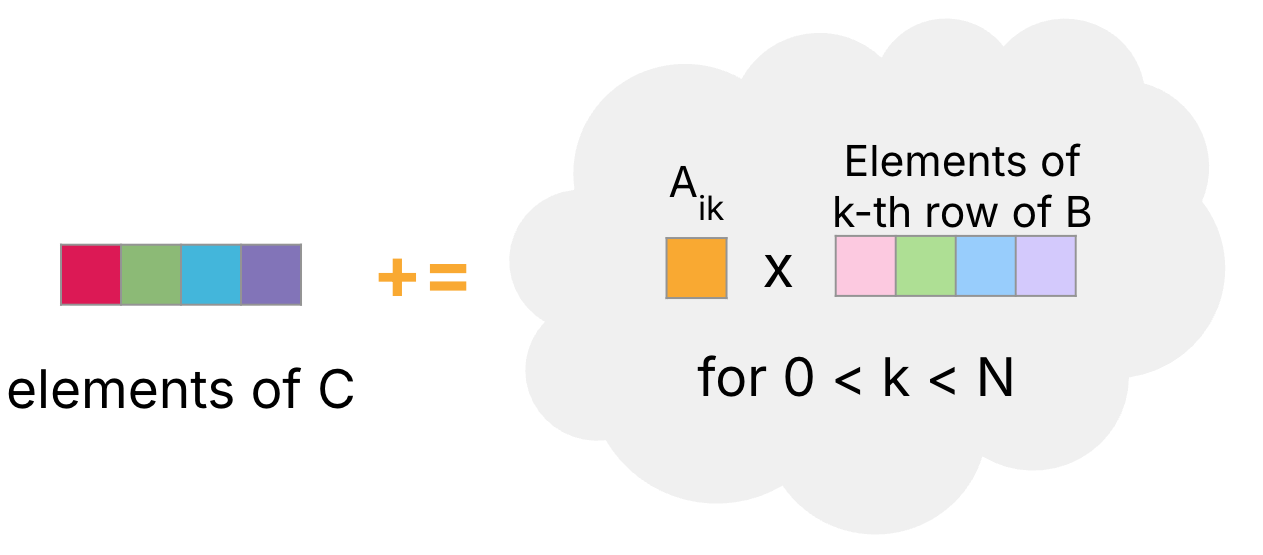
Figure 3:Compute four elements of C (starting with ) by iteratively adding the result of scaling four elements of the -th row of B (starting with ) with .
We can extend this idea to a tiled SIMD approach shown in Figure 4.
Figure 4:SIMD dgemm tiled matrix multiplication. The outlined boxes indicate which values are loaded into the 256-bit-wide registers. Use the menu bar to trace through the animation or access the original Google Slides.
Show Explanation
Figure 4 shows an 8-by-8 matrix multiplication.
i = 0. Compute elements for ; let this be . Let be the corresponding part of the -th row of .1a through 1h: Loop through . Compute the result of \vec{b}\vec{c}$.
i = 0, still. Next, compute elements for ; let this be . Let be the corresponding part of the -th row of . Again, loop through the index to add the resulting scalar-by-vector to the elements of .i = 1. Compute elements for .i = 1. Compute elements for .
The “tiled” cache blocking SIMD approach performs slightly worse than the transposed SIMD approach.
C 0.768672 seconds
registers: 0.277462 seconds
simd,naive: 0.416584 seconds
simd,transpose: 0.275622 seconds
simd,tiled: 0.356344 seconds5DGEMM 10: GCC Optimization¶
Finally, let’s compile using different gcc optimization flags. In Table 1, we can see that even with mild gcc optimizations like -O1, SIMD vastly outperforms any SISD approach.
Table 1:DGEMM SIMD runtime (in seconds) with different optimization flags.
Program |
|
|
|
|
|---|---|---|---|---|
DGEMM (original) | 0.768672 | 0.197168 | 0.197538 | 0.193889 |
0.277462 | 0.191474 | 0.191921 | 0.126439 | |
0.416584 | 0.048405 | 0.049970 | 0.049045 | |
0.275622 | 0.031824 | 0.032188 | 0.031978 | |
0.356344 | 0.033386 | 0.035177 | 0.037030 |
Generally speaking, most of the speedup comes not from doing multiple math operations at a time, but instead from doing a large memory load/store at a time.
6DGEMM SIMD Code¶
The three algorithsm discussed in this section leverage Intel SIMD extensions. You will see in the code below that the SIMD instructions are written in C as Intel Intrinsics. More next!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17matrix_d_t *dgemm_simd(matrix_d_t *A, matrix_d_t *B) { if (A->ncols!=B->nrows) return NULL; matrix_d_t *C = init_mat_d(A->nrows, B->ncols); for (int i = 0; i < A->nrows; i++) { for (int j = 0; j < B->ncols; j+=4) { // 4 doubles at a time avx256_t v_C = avx_load(C->data + i*C->ncols +j); for (int k = 0; k < A->ncols; k++) { avx256_t s_A = avx_set_num(A->data[(i*A->ncols)+k]); avx256_t v_B = avx_load(B->data+k*B->ncols+j); // C_ij += a_ik * B_jk (for j = 0...3) v_C = avx_mul_add(s_A, v_B, v_C); } avx_store(C->data+i*C->ncols+j, v_C); } } return C; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32matrix_d_t *dgemm_simd_transpose(matrix_d_t *A, matrix_d_t *B) { if (A->ncols!=B->nrows) return NULL; matrix_d_t *C = init_mat_d(A->nrows, B->ncols); matrix_d_t *B_T = transpose_mat_d(B); for (int i = 0; i < A->nrows; i++) { for (int j = 0; j < B->ncols; j++) { double *ptr_A = A->data+(i*A->ncols); double *ptr_B_T = B_T->data+(j*B_T->ncols); int k = 0; // 4 doubles at a time avx256_t v_C = avx_set_num(0); for (; k < A->ncols/4*4; k+= 4) { avx256_t v_A = avx_load(ptr_A+k); avx256_t v_B = avx_load(ptr_B_T+k); v_C = avx_mul_add(v_A, v_B, v_C); } double mem[4] __attribute__ ((aligned (64))); avx_store(mem, v_C); double sum = mem[0] + mem[1] + mem[2] + mem[3]; // tail case for(; k < A->ncols; k++) { sum += ptr_A[k]*ptr_B_T[k]; } C->data[i*C->ncols+j] = sum; } } free_mat_d(B_T); return C; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27static inline void matmul_simd_tile(int si, int sj, int sk, matrix_d_t *A, matrix_d_t *B, matrix_d_t *C) { for (int i = si; i < si + BLOCKSIZE; i++) { for (int j = sj; j < sj + BLOCKSIZE; j+=4) { // 4 doubles at a time avx256_t v_C = avx_load(C->data+i*C->ncols+j); for (int k = sk; k < sk + BLOCKSIZE; k++) { avx256_t s_A = avx_set_num(A->data[(i*A->ncols)+k]); avx256_t v_B = avx_load(B->data+k*B->ncols+j); v_C = avx_mul_add(s_A, v_B, v_C); } avx_store(C->data+i*C->ncols+j, v_C); } } } matrix_d_t *dgemm_simd_block(matrix_d_t *A, matrix_d_t *B) { if (A->ncols!=B->nrows) return NULL; matrix_d_t *C = init_mat_d(A->nrows, B->ncols); for (int si = 0; si < A->nrows; si += BLOCKSIZE) { for (int sj = 0; sj < B->ncols; sj += BLOCKSIZE) { for (int sk = 0; sk < A->ncols; sk+= BLOCKSIZE) { matmul_simd_tile(si, sj, sk, A, B, C); } } } return C; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15matrix_d_t *dgemm(matrix_d_t *A, matrix_d_t *B) { if (A->ncols != B->nrows) return NULL; matrix_d_t *C = init_mat_d(A->nrows, B->ncols); for (int i = 0; i < A->nrows; i++) { for (int j = 0; j < B->ncols; j++) { double sum = 0; for (int k = 0; k < A->ncols; k++) { sum += A->data[i*A->ncols+k]*B->data[k*B->ncols+j]; } C->data[i*C->ncols+j] = sum; } } return C; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22typedef __m256d avx256_t; // Loads 8 doubles at memory address A into a avx256_t static inline avx256_t avx_load(double *A) { return _mm256_load_pd(A); } // Stores the avx256_t at SRC to DST. Each avx256_t element gets stored in a // different index of the array passed into DST. static inline void avx_store(double *dst, avx256_t src) { _mm256_store_pd(dst, src); } // Creates a avx256_t where every element is equal to num static inline avx256_t avx_set_num(double num) { return _mm256_set1_pd(num); } // A * B + C static inline avx256_t avx_mul_add(avx256_t A, avx256_t B, avx256_t C) { return _mm256_fmadd_pd(A, B, C); }
In Figure 1, we assume a cache that has 256-bit blocks. This carries over the cache assumption from our cache blocking discussion.